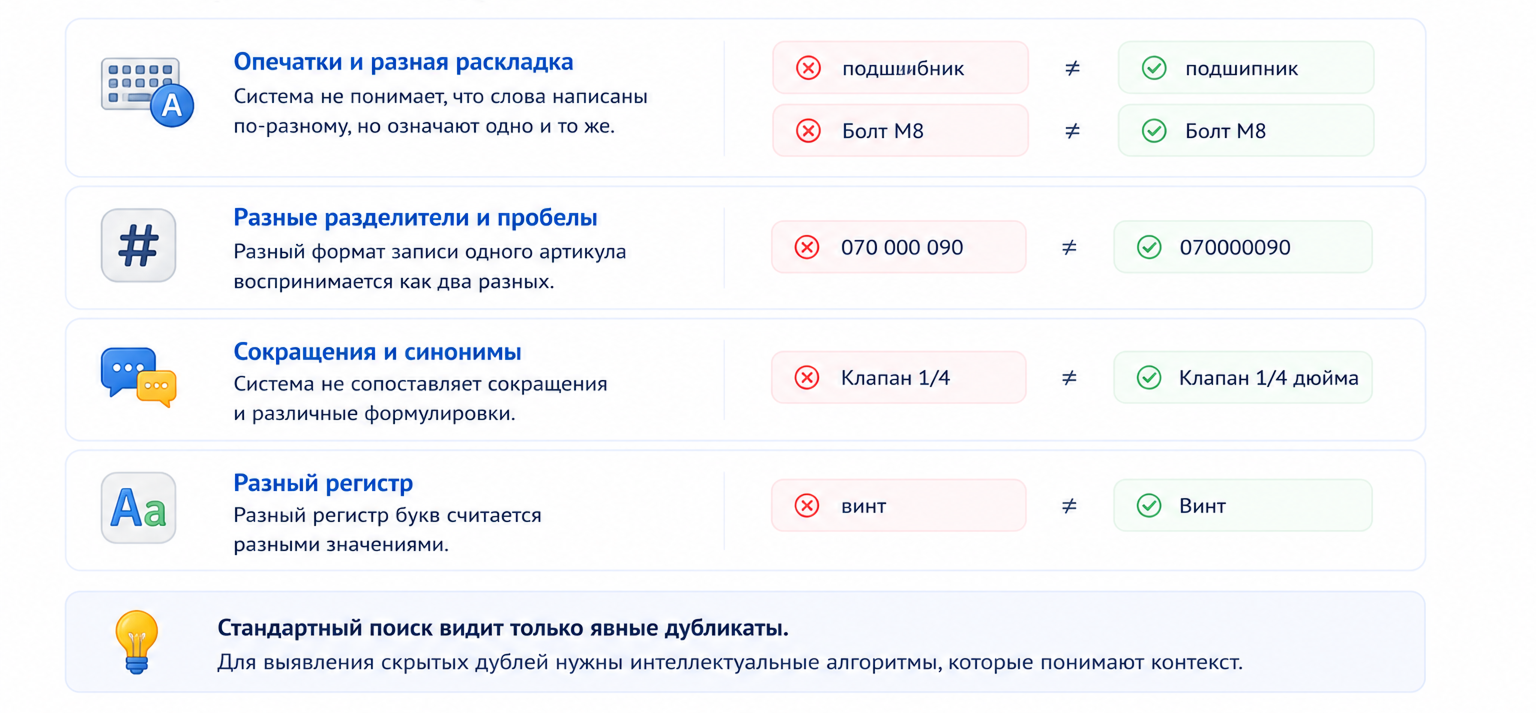
Неструктурированные справочники с тысячами скрытых дубликатов - это системная проблема, которая ежедневно приводит к прямым финансовым потерям. Продолжать работать с такими данными - значит сознательно игнорировать убытки и неэффективное использование оборотных средств.
Мы внедрим ИИ-агента "Нормализатор НСИ" в ваши системы 1С и Битрикс24. Он проведет полный аудит справочника с помощью технологии нечеткого поиска, выявит до 95% скрытых дубликатов и автоматически устранит их. Агент настроит единые стандарты для наименований и будет контролировать создание новых позиций, чтобы поддерживать порядок в данных постоянно.
В результате вы получите полностью прозрачные и достоверные данные о складских остатках, что позволит сократить затоваривание и оптимизировать закупки. Ваши менеджеры будут тратить секунды, а не минуты, на поиск нужных товаров, а аналитические системы начнут работать с корректной информацией.
Свяжитесь с нами, чтобы обсудить, как технология fuzzy matching может навести порядок в ваших справочниках. Мы проанализируем специфику вашей номенклатуры и предложим решение, которое устранит существующие проблемы и предотвратит их появление в будущем.